- Published on
Session Management Fundamentals
- Authors
- Name
- Abhinav Pandey
- @abh1navv


Session Management Fundamentals

Table of Contents
- Session Management Fundamentals
- Introduction
- A simple session management flow
- The need for authentication
- The need for authorization
- The purpose of access tokens
- Session expiry
- Access Tokens
- Reference Tokens
- Authorization flow
- Considerations when using Reference Tokens
- Value Tokens
- Authorization flow
- JWT Structure
- Considerations when using JWTs
- Conclusion
Introduction
Session management is the process of maintaining a session "between a client and a server", "for a user", "for a period of time".
A simple session management flow
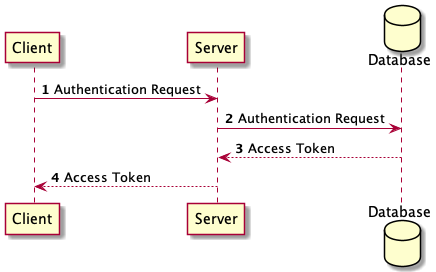
The process can be described as follows:
- A user authenticates with their credentials using a client application(such as a web browser).
- The server receives the request and creates a session for the user.
- The server sends an access token to the client.
- For subsequent requests, the client uses the access token to request the server on behalf of the user.
- When the server receives the request, it checks the access token and if it is valid, the server is able to figure out the actions the user is authorized to perform.
- This process continues until the user logs out or the session expires. In that case, the access tokens are deleted.
Let's look at the highlighted terms of the session management process.
The need for authentication

- to know who the user is. In deeper terms, to associate the actions of the user with their identity. If I open the Twitter website and hit like on a post, Twitter should be able to associate that like with my identity.
- an important point to note in context of web applications is that authentication always involves a user interaction, be it just a click of a button.
The need for authorization
- Every user has a set of permissions. These permissions are granted to the user by the server. For example, I can like any post, but I can only delete my own posts or edit my own profile.
- In theory, every request a user makes to the server is validated against the permissions that the user has.
- In practice, a server implicitly lets all users perform a few actions but requires authorization for all other actions.
The purpose of access tokens
- The access token is a unique identifier for the session. It can be linked to the user's identity and their permissions.
- Its purpose is to enable the user to perform actions on the server without having to authenticate on every request.
Session expiry
- The session expires after a period of time. This needs to be handled in the implementation of the access token.
- Expiry is an intuitive concept because it wouldn't make sense to have a session that lasts forever.
Access Tokens
Access tokens can be broadly classified into two categories:
Reference Tokens
These are tokens that are used to identify the user and their permissions but do not hold this information themselves.
- A usual implementation of reference tokens is a random string.
- The string should be unique for every user.
- It should also be long enough to be difficult to guess.
- It points to the user's identity and permissions in a storage. The storage can be a database, a distributed cache like Redis or in memory objects of the server.
Authorization flow

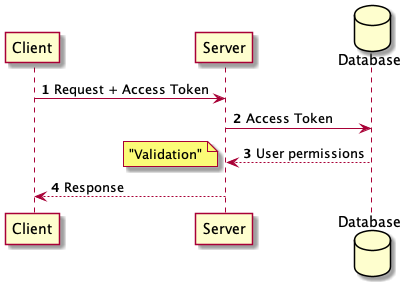
- The client sends a request to the server - the access token is sent as a header.
- The server verifies the access token's validity by querying the storage for it. The storage returns the permissions against that token.
- Checking the validity involves
- checking that the token exists in the storage
- checking that the token is not expired.
- if all is well till here, the server checks the permissions of the user against what is requested in the request.
- The server returns the response to the client
Considerations when using Reference Tokens
As we can see, each request requires a storage interaction. This can be a costly operation depending on the storage being used. The impact can be measured using a few parameters
- request throughput,
- fault tolerance,
- scalability.
Let's compare these three attributes for each of the three storage types.
-
In-memory storage - The database stores the permissions permanently and additionally, the sessions and the permissions in effect are stored in an in-memory object.
- request throughput: It's very fast to read from in-memory objects. Good
- fault tolerance: If the server goes down, all sessions are lost. Fairly unacceptable
- scalability: If servers need to be used in clusters, session created on one server does not work. This leads to the need for sticky sessions. They require a overhead in implementation and are not preferred because they can lead to a skew in server load. In short, saving data on the servers does not work in the favor of scalability Bad
-
Databases
- request throughput: It's not very fast to read from databases or any kind of persistent storage. This can reduce the number of requests your application can serve concurrently Bad
- fault tolerance: If the database server goes down, sessions are not lost but temporarily it is not possible to create sessions or authorize users during the downtime. However, database downtime is something that can be avoided if extra care is taken to create a fault tolerant database architecture. Any large scale application is likely to plan for this. Fairly acceptable
- scalability: A database allows the servers to scale as needed. Good
-
Redis(or any other distributed cache) - The database stores the permissions permanently and additionally, the sessions and the permissions in effect are stored in a distributed cache.
- request throughput: It's faster to read from Redis than databases. Fairly acceptable
- fault tolerance: If the Redis server goes down, all sessions are lost and cannot be recovered. Nor can new sessions be created during the downtime. Fairly unacceptable
- scalability: It allows the application servers to scale as needed. However, as the user activity increases, Redis will require scaling of its own infrastructure. This is completely normal in web applications. Fairly acceptable
| Storage Type | Request Throughput | Fault Tolerance | Scalability |
|---|---|---|---|
| In-memory storage | Good ✅ | Unacceptable 🟠 | Bad ❌ |
| Databases | Bad ❌ | Acceptable🟡 | Good ✅ |
| Redis | Acceptable🟡 | Unacceptable 🟠 | Acceptable 🟡 |
Value Tokens
These are tokens that hold the user's identity and their permissions. They are stored on the client side.
- They can be encrypted or encoded strings.
- They must contain details which uniquely identify the user, like a username or a userid.
- They may contain additional information such as the expiry time so that they can self-invalidate after a time.
- The ultimate goal of a value token is to provide authorization without needing interaction with any external storage.
Authorization flow

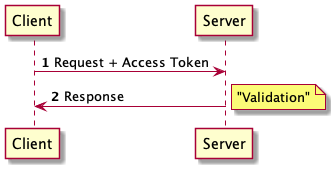
- The client sends a request to the server - the access token is sent as a header. The server verifies the access token's validity by reading its content. Checking the validity involves:
- decrypting/decoding the token's content.
- checking that the token is not expired using the expiry time in the token content.
- If all is well till here, the server checks the permissions of the user against what is requested. This permission information is part of the token content itself so no database queries are required.
- The server returns the response to the client.
To understand this deeper let's talk about an exact implementation of value tokens - Json Web Tokens (JWT).
JWT Structure
Example JWT:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9. eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9. TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
- Italic part - header - JSON object that contains the algorithm and type of token. Base64URL encoded.
- Middle part - payload - JSON object that contains the user's information, permissions and expiry time. Base64url encoded.
- Bold part - signature - a string which only the server can understand.
Signature is created using the algorithm used in the header. The server uses a secret key to sign the payload and header. Only the server knows the key required to create or understand the signature.
If you decode the same JWT on jwt.io, you can see what's inside.

Signature creation Signature = Algorithm((header+payload)*secretKey)
Signature verification Create another signature using the same algorithm and secret key. Compare it with the signature received in the request. Algorithm((header + payload)*secretKey) == Signature
Considerations when using JWTs
- Both header and payload can be encoded/decoded by anyone and read. So do not store anything sensitive like a password in it. If there is some sensitive information in the payload, encrypt it.
- If a JWT is leaked, the attacker can use it to access the resource as long as it is valid. This poses a question about how long the JWT should be valid. We will cover this in the next article when we talk about more advanced concepts.
- In contrast, a reference token works better in this scenario - The server controls it, so it can revoke it on demand if either the server or the victim are able to detect the theft.
- The only way to revoke a JWT is to change the secret key. This is not recommended as it will invalidate sessions for all your users. This is however easy to do and can be an option during incident response.
Conclusion
We looked at a simple session management flow and we looked at two types of access tokens that can be used to implement it. Both have their pros and cons and none of them is a silver bullet. This flow works fine for a simple web application but it lacks a few key features which can make it inadequate for critical applications.
In the next article, we will talk more about security, scalability and user experience aspects of session management. We will also utilise an open source library Supertokens to implement an improved session management flow.
Thanks for reading. Stay tuned for more on session management. If you want to connect with me, you can find me on Twitter